
De un Contact Center reactivo a un Contact center que maneja proactiva la relación con el cliente
Para muchas empresas, el contact center es la habitación donde la promesa de marca se rompe. El cliente del banco al que le han bloqueado la tarjeta y lleva tres transferencias explicando lo mismo. La persona que cambió su cita médica por la app, recibió la confirmación, y cuando llama a confirmar le dicen que no consta. El comprador online cuyo pedido llegó defectuoso, ya abrió una incidencia por email, y ahora llama por tercera vez mientras el agente busca en cuatro sistemas distintos para encontrar lo que ya explicó dos veces. Escenarios distintos, misma causa raíz: una arquitectura de atención al cliente diseñada para gestionar canales, no para gestionar la relación con el cliente.
El CRM tradicional nació para almacenar. El de segunda generación aprendió a segmentar. El CRM inteligente —o más preciso, el Customer Engagement Layer— hace algo cualitativamente diferente: orquesta. Orquesta canales, agentes de IA, contexto del cliente y acciones sobre los sistemas de la empresa desde un único plano de inteligencia, en tiempo real, de forma continua. El agente que recibe la llamada ya sabe quién llama, qué pasó en los últimos siete días, cuál es la acción más probable y qué herramientas tiene para resolverlo antes de que el cliente diga una palabra.
Los resultados de quienes ya operan con este modelo son concretos: mejora radical en calidad y churn, ROI superior al 45% en el primer año, reducción de más del 80% en el coste por interacción resuelta sin intervención humana. Pero hay algo que las métricas no capturan bien: crear un agente ya no requiere un equipo de ingeniería ni seis meses de desarrollo. Requiere el responsable del proceso, instrucciones en lenguaje natural y resultados visibles en días. Eso cambia quién construye la inteligencia del contact center, y cómo se organiza la empresa alrededor de ese proceso.
El punto de partida que nadie pone en las presentaciones
Hay tres datos operativos que definen el estado real de los contact centers en grandes organizaciones de servicios. No son predicciones ni benchmarks de analistas. Son métricas observadas en operaciones reales —banca, seguros, utilities, salud, retail— y cada una cuenta una historia distinta sobre el mismo problema de fondo.
- El primero: más de dieciséis sistemas diferentes que un agente del contact center abre en cada turno. CRM en uno. Gestión de contratos en otro. Histórico de incidencias en un tercero. Estado del pedido o del servicio en un cuarto. Gestión de tickets en un quinto. Cada sistema fue implementado en su momento para resolver un problema concreto. Ninguno habla con los demás de forma nativa. El agente humano es el único integrador disponible, y lo hace manualmente, en tiempo real, mientras el cliente espera. El resultado no es solo lentitud: es una experiencia de atención que depende de las habilidades personales del agente más que del diseño del sistema.
- El segundo: el 40% de los clientes vuelven a llamar en los siete días siguientes a una incidencia. Esta tasa de rellamada es el indicador más honesto de la resolución real en primer contacto. Cuando un cliente llama por segunda vez en siete días, la mayoría de las veces es porque la primera llamada no resolvió nada. Ese contacto costó dinero a la empresa, generó frustración al cliente, y no produjo ningún resultado útil. La rellamada no es un problema de volumen de llamadas. Es un indicador directo de calidad de proceso.
- El tercero: diez minutos de tiempo medio para resolver lo que el cliente ya había explicado. No para resolver el problema completo. Para reconstituir el contexto que debería haber viajado con el cliente desde el primer contacto. El cliente que explicó su problema al chatbot lo repite al IVR, lo repite al primer agente, y si hay una transferencia, lo repite una cuarta vez. Ocho minutos de coste puro.
Estos tres indicadores señalan el mismo diagnóstico: el problema no es la falta de tecnología sino la ausencia de una capa de inteligencia unificada que conecte cada punto de contacto con un contexto continuo del cliente. Sin esa capa, cada herramienta añadida es un silo más que el agente humano integra a mano. Y la acumulación de silos no se resuelve con más herramientas. Se resuelve rediseñando la arquitectura.

Los errores que las empresas llevan repitiendo
Antes de describir cómo se construye un modelo de contact center inteligente, conviene ser explícito sobre por qué los modelos anteriores no han funcionado. Hay cuatro patrones de error que reaparecen sistemáticamente en todo tipo de sectores. No son accidentes. Son consecuencias predecibles de tomar las decisiones en el orden incorrecto.
Error 1: Automatizar el proceso roto
Una aseguradora implementa un chatbot para gestionar consultas sobre el estado de siniestros. El chatbot se conecta al mismo sistema de gestión de expedientes fragmentado que ya usaba el agente humano. El cliente entra, el bot no puede resolver la consulta porque no tiene acceso completo al contexto, y transfiere al agente con cero información sobre lo que el cliente ya explicó. El bot ha reducido el volumen de llamadas que llegan al primer nivel. No ha reducido el volumen de clientes frustrados. Ha desplazado la frustración un paso antes en el proceso.
Automatizar un proceso roto no produce un proceso automático que funciona. Produce un proceso roto que funciona más rápido. La secuencia correcta es rediseñar el proceso primero, verificar que funciona bien con agentes humanos, y luego escalar con IA lo que ya estaba funcionando. Este orden no es negociable, y su inversión es la causa raíz de la mayoría de fracasos en la transformación de los procesos de cliente.
Error 2: Implementar IA sobre datos fragmentados
Los modelos de IA para contact center requieren datos de calidad: historial de interacciones, estado del servicio contratado, historial de facturación, incidencias previas, propensión a la baja. En la mayoría de empresas esos datos existen. El problema es que están distribuidos entre cinco, ocho o doce sistemas que nunca fueron diseñados para integrarse entre sí. Un modelo de churn entrenado sobre datos del CRM sin acceso al historial de incidencias de servicio del mismo cliente no predice la baja con precisión real. Predice algo que se parece a la baja pero con un error demasiado alto para ser accionable en producción.
El resultado es siempre el mismo: el modelo funciona en el piloto, donde los datos se prepararon manualmente. En producción, los datos llegan fragmentados y el modelo se degrada hasta hacerse irrelevante. La conclusión que extrae el equipo suele ser «la IA no funciona en nuestro contexto». La conclusión correcta es que la arquitectura de datos no estaba preparada para la IA. Son dos problemas distintos con la misma solución pendiente: construir la capa de datos unificada primero.
Error 3: Pilotos que no escalan
Las grandes organizaciones tienen, en promedio, entre veinte y cuarenta proyectos de IA activos simultáneamente. La mayoría llevan entre uno y tres años en fase de piloto. El paso de piloto a producción a escala es donde mueren la mayoría. Las razones son siempre las mismas: los datos del piloto se prepararon manualmente, la integración con los sistemas existentes es mucho más costosa de lo previsto, el modelo no tiene el gobierno necesario para operar en producción, y no hay un propietario de negocio claro que responda por el resultado.
La pregunta que hay que hacerse no es «¿cuántos pilotos de IA tenemos?» sino «¿cuántos proyectos de IA están en producción con KPIs de negocio medidos?». La diferencia entre esas dos respuestas es la brecha real entre el discurso de transformación y la transformación efectiva.
Error 4: Tratar la transformación como un proyecto de IT
La transformación del contact center con IA no es un proyecto tecnológico. Es un proyecto de rediseño de operaciones que usa tecnología como habilitador. Cuando la iniciativa vive en IT, el éxito se mide técnicamente: ¿el modelo está desplegado?, ¿la integración funciona?, ¿el uptime es correcto? Cuando vive en operaciones, el éxito se mide en negocio: ¿ha bajado la tasa de rellamada?, ¿ha subido el FCR?, ¿ha bajado el coste por interacción? Los proyectos que generan ROI real tienen un propietario de negocio que responde por métricas de negocio, con IT como soporte. Los que generan informes técnicos impecables pero sin impacto en el cliente tienen la propiedad invertida.
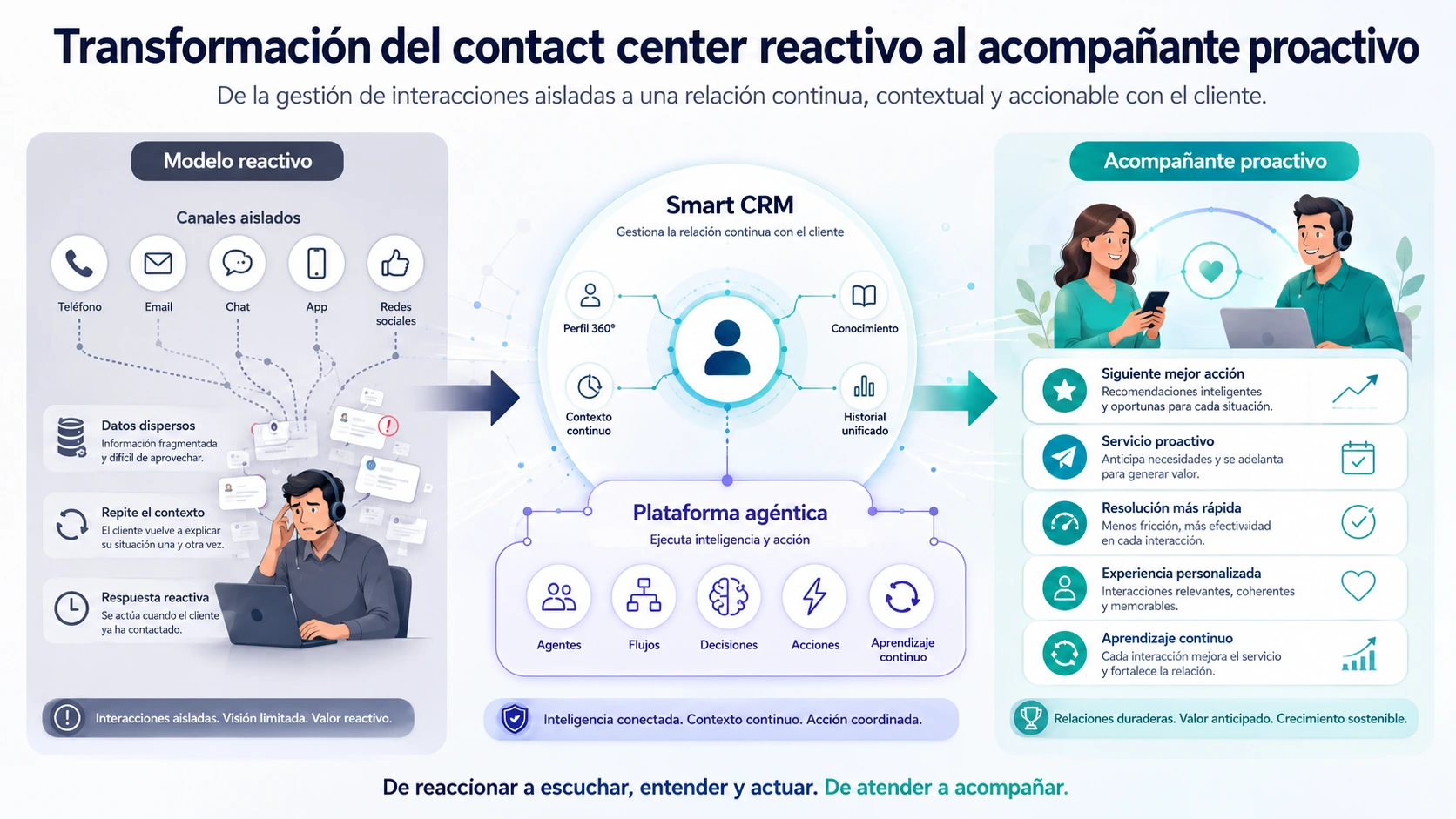
El cambio de modelo: de gestionar canales a gestionar conversaciones
Hay una frase que resume el problema de fondo mejor que cualquier análisis técnico: «Hoy gestionamos canales. Mañana gestionaremos conversaciones.» La diferencia no es semántica. Es arquitectónica. Un modelo orientado a canales optimiza cada canal de forma independiente: el chatbot tiene sus métricas, la voz las suyas, la app las suyas. El cliente que cambia de canal pierde el contexto acumulado. Cada canal es un punto de inicio, no una etapa de un proceso continuo.
Un modelo orientado a conversaciones parte de una premisa opuesta: la unidad de medida no es el contacto sino la conversación completa del cliente con la empresa, que puede extenderse en el tiempo a través de múltiples canales y momentos. Cuando un cliente de banca que llamó ayer por voz abre hoy un chat, el sistema ya sabe quién es, qué problema tiene, qué se hizo ayer y cuál es la acción más probable para resolver su caso. No porque un agente tomara notas. Sino porque existe una capa de inteligencia conversacional que mantiene ese contexto de forma continua, automática y estructurada.
Este cambio implica tres transformaciones arquitectónicas simultáneas: una capa de canales unificada (voz, chat, app, IVR, atención presencial o de campo) que no trata cada canal como un silo; una capa de inteligencia de conversación que infiere en tiempo real la intención del cliente, accede a la base de conocimiento relevante, analiza el sentimiento y evalúa la calidad de la interacción antes de que termine; y un panel de control común que gobierna datos, agentes, reglas de negocio y supervisión humana desde un único plano de gestión. Sin las tres capas integradas, el resultado sigue siendo fragmentado.
Los cuatro pilares del CRM inteligente
El modelo de CRM inteligente se sostiene sobre cuatro capacidades que deben estar presentes de forma integrada. No son capas que se implementan de forma independiente: cada una presupone la anterior y habilita la siguiente. La organización que tiene la primera sin la segunda tiene agentes con acceso a herramientas pero sin contexto para usarlas bien. La que tiene datos y contexto pero no orquestación multi-agente tiene el mapa pero no el navegador.
Work IQ: la inteligencia en el flujo de trabajo
Work IQ conecta a los empleados a través del contexto de trabajo, habilitando la colaboración fluida entre personas y agentes. En la práctica es la diferencia entre el agente de soporte de una empresa de software que abre doce sistemas para reconstruir el caso de un cliente, y uno que tiene un asistente inteligente que ya consolidó toda esa información antes de que descuelgue. Work IQ no reemplaza al agente. Cambia radicalmente qué hace: en lugar de invertir el 80% del tiempo buscando información, lo invierte en lo que ningún sistema puede hacer —empatizar, negociar, decidir en situaciones ambiguas, retener a un cliente que está a punto de irse.
Business IQ: la ontología del negocio como capa de contexto
Business IQ proporciona contexto de negocio a través de una ontología semántica que permite a los agentes de IA razonar sobre la realidad de la empresa. Sin esa ontología, los datos existen pero son ruido. Con ella, son señal accionable: un cliente de alto valor de una aseguradora con tres reclamaciones abiertas en el último mes, dos llamadas sin resolución y una póliza de renovación próxima no es solo un registro en base de datos. Es una situación de riesgo con una acción proactiva clara.
La ontología de negocio integra dominios de datos que históricamente han vivido separados: datos operativos (estado del servicio, incidencias abiertas, historial de entregas o prestaciones), datos de cliente (contrato, historial de interacciones, propensión), datos de facturación y datos de atención (tickets, resoluciones, sentimiento). Construirla es el trabajo más difícil de la transformación y el que más se subestima en los proyectos que fracasan. No es un proyecto de tres meses. Es la inversión estructural que hace posible todo lo demás.
Knowledge IQ: los agentes que colaboran y actúan
Knowledge IQ habilita la orquestación multi-agente fundamentada sobre ese contexto. No basta con que los agentes tengan acceso a la información: necesitan colaborar entre sí para resolver casos complejos. En una empresa de suministro energético, un agente de detección de problemas de servicio que identifica un corte activo puede activar a un agente de notificación proactiva al cliente, que consulta al agente de historial de interacciones para determinar el canal correcto de comunicación, que finaliza con un agente de resolución que ejecuta la acción en los sistemas de back-end de la empresa. Todo esto sin intervención humana cuando el caso lo permite, escalando al agente humano solo cuando la complejidad o el riesgo lo justifican.
En organizaciones con alta madurez en este pilar, más del 30% de los contactos son iniciados proactivamente por la empresa antes de que el cliente llame. En banca esto puede ser una alerta de cargo inusual con opción de bloqueo inmediato. En retail, la notificación de un retraso en entrega con propuesta de solución antes de que el cliente descubra el problema. En salud, un recordatorio de seguimiento post-consulta que anticipa la llamada del paciente.
Web IQ: grounding en tiempo real sobre el mundo exterior
Web IQ cierra una brecha que los sistemas anteriores no podían resolver: fundamentar las respuestas de los agentes en información externa verificable en tiempo real. El estado actual de una reclamación publicada ayer en la web corporativa, las condiciones de una promoción lanzada esta mañana, los cambios regulatorios publicados la semana pasada. Ninguna base de conocimiento estática puede seguir ese ritmo de actualización. Web IQ accede a fuentes autorizadas en tiempo real, verifica la información y la incorpora a la respuesta sin que nadie la haya introducido manualmente. En sectores con regulación cambiante —banca, seguros, salud, energía— esta capacidad tiene impacto directo en la calidad y el cumplimiento de las respuestas.
Flujos y agentes: la unidad básica de la automatización inteligente
Uno de los debates más estériles que aparece en los proyectos de automatización con IA es la discusión entre «¿usamos flujos o usamos agentes?». La pregunta está mal formulada. La automatización inteligente es el resultado de crear flujos dentro de los cuales hay nodos de código y nodos de agente. Flujos y agentes no son paradigmas en competencia. Son componentes complementarios de la misma arquitectura, y la decisión de cuándo usar uno u otro se toma nodo a nodo, no como decisión de diseño global.
La distinción tiene implicaciones de coste directas: un nodo de código ejecuta lógica determinista a coste de cómputo estándar; un nodo de agente consume tokens de LLM en cada ejecución. Una clasificación de tipos de incidencia que se puede resolver con reglas explícitas no necesita un agente: un nodo de código es más rápido, más predecible y tres órdenes de magnitud más barato a escala. Una situación que requiere razonamiento sobre contexto ambiguo, adaptación a instrucciones en lenguaje natural o selección entre herramientas disponibles justifica el coste del agente. La arquitectura óptima mezcla ambos según la naturaleza de cada nodo, y esa mezcla se decide y ajusta de forma iterativa mientras se construye el flujo —no en un documento de diseño de cien páginas elaborado meses antes.
Aquí aparece un segundo error frecuente que conviene nombrar explícitamente: confundir agentes con chatbots. Un chatbot es un sistema de respuesta secuencial a inputs del usuario, generalmente basado en árboles de decisión o flujos predefinidos. Un agente es una entidad autónoma que toma decisiones en función de un prompt de sistema y las herramientas disponibles para ella. La diferencia no es de interfaz: es de arquitectura. Un agente puede ejecutarse sin ninguna interacción con el usuario: detecta una anomalía en los datos de un cliente, razona sobre qué acción es la correcta dadas las herramientas disponibles, ejecuta la acción y reporta el resultado. Llamarle «chatbot» no es solo incorrecto. Lleva a diseñarlo mal y a subestimar sistemáticamente lo que puede hacer.
Crear agentes es iterativo e interactivo: romper el ciclo especificación-espera-decepción
La creación de agentes rompe las fronteras tradicionales entre usuario, sistemas y flujos de una forma que la mayoría de organizaciones no ha procesado aún. Crear un agente no requiere un documento de especificación funcional de ciento veinte páginas, un ciclo de desarrollo de seis meses y una reunión de aceptación formal. Requiere un entorno configurado, un prompt en lenguaje natural y la posibilidad de ver el resultado en tiempo real. Cualquier persona con acceso al entorno y criterio sobre el proceso puede crear y evolucionar un agente directamente.
Esto tiene dos implicaciones que cambian la forma de trabajar con proveedores e integradores. La primera: el ciclo de desarrollo ya no es secuencial (especifico, espero meses, recibo, descubro que no es lo que quería, vuelvo a empezar). Es iterativo y paralelo: el responsable del proceso y el integrador construyen el agente en sesiones conjuntas, con resultados visibles desde el primer día. La segunda: el responsable del proceso no puede seguir siendo un observador externo del desarrollo. Tiene que estar en la sala, entender lo que el agente hace, y ser capaz de identificar cuándo el comportamiento del agente no coincide con la lógica real del proceso. Si quien diseña el proceso no entiende lo que se está construyendo con IA, el resultado será técnicamente correcto y operativamente incorrecto. La historia de los proyectos tecnológicos lleva décadas repitiendo esa misma lección.
AI-First: cuando todo el desarrollo se hace con IA
La transformación con IA no termina en los agentes desplegados. Incluye también cómo se construyen esos agentes y los sistemas que los soportan. En un modelo AI-First, el código que implementa los nodos del flujo se genera con IA, los tests se diseñan con IA, la documentación se mantiene con IA. No como aspiración de eficiencia, sino como estándar operativo. El desarrollador que no usa IA para generar código trabaja a una fracción de la velocidad de quien sí lo hace, con un coste equivalentemente más alto.
Esto tiene una implicación directa para la gestión de proveedores: si un integrador usa IA para desarrollar y el responsable del cliente no entiende cómo lo hace, hay un punto ciego de supervisión que es también un riesgo de calidad. El gestor del contrato que no puede evaluar si el código generado por IA del proveedor es correcto, seguro y mantenible no está gestionando el contrato. El estándar mínimo de supervisión en un modelo AI-First incluye entender qué se genera automáticamente, qué se revisa manualmente y con qué criterio de calidad antes del despliegue.
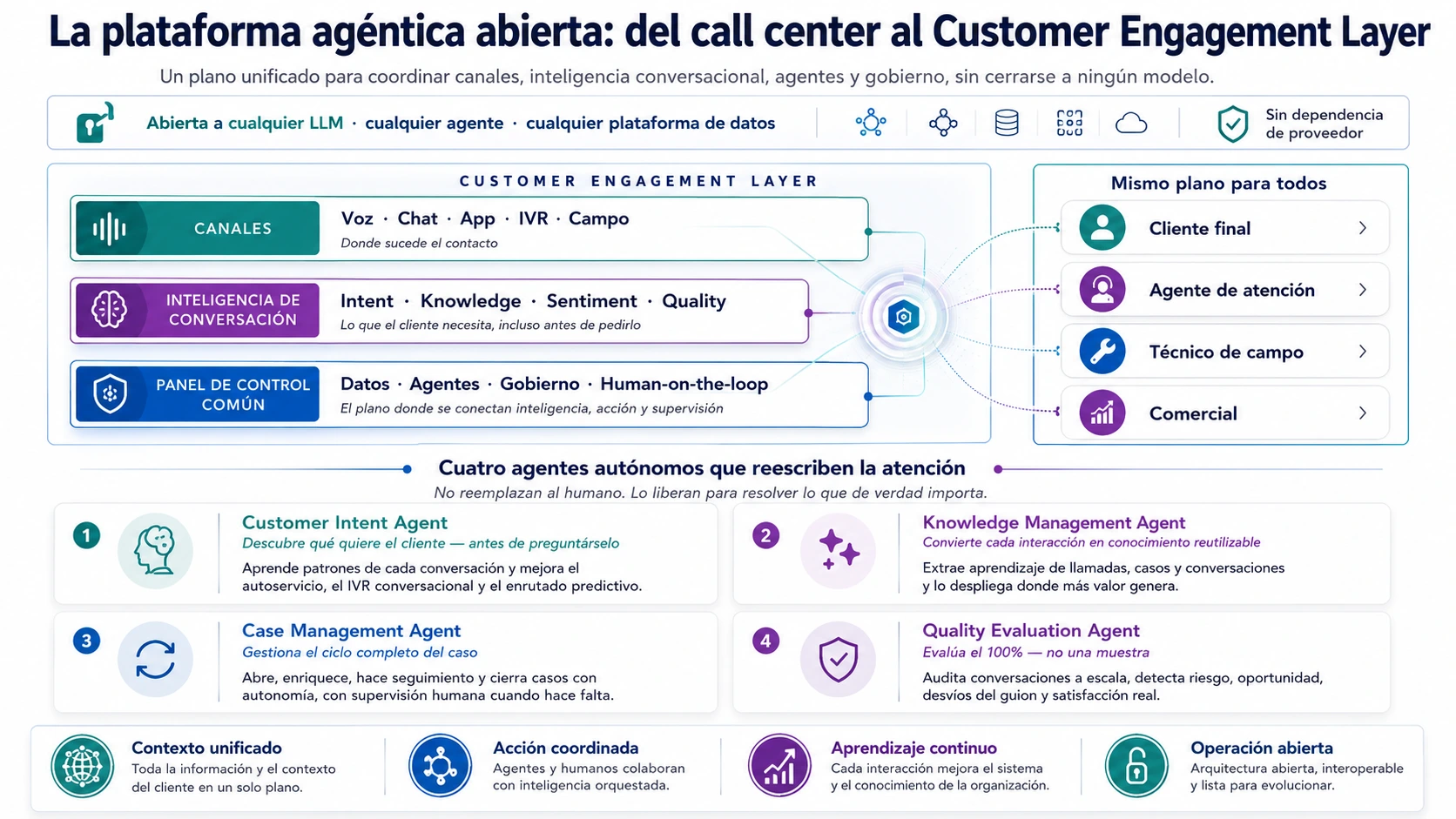
La plataforma agentica: orquestación sin cerrarse a ningún modelo
El núcleo tecnológico que hace posible este modelo es la plataforma agentica: una infraestructura de orquestación multi-agente capaz de coordinar modelos de lenguaje, agentes especializados, sistemas de datos y acciones sobre los sistemas operativos de la empresa. La característica más importante de una plataforma agentica madura no es la sofisticación de sus modelos de IA. Es su capacidad de funcionar con cualquier LLM, cualquier agente y cualquier plataforma de datos sin quedar atada a un proveedor específico.
En arquitectura, esto se traduce en tres capas. La capa de datos unifica las fuentes de información en un lago lógico único, sobre el que se construye la ontología de negocio y los agentes de datos especializados. La capa de plataforma agentica gestiona la orquestación multi-agente con bucles de retroalimentación cerrados que permiten al sistema aprender de cada interacción y mejorar sus respuestas futuras. La capa de ingeniería agentica cubre todo el ciclo de vida de los agentes: planificación, desarrollo, test, despliegue y operación, con un repositorio de especificaciones, CI/CD y capacidades nativas para el desarrollo agentico.
El principio de apertura es estratégicamente crítico por una razón que se subestima con frecuencia: el modelo que era el mejor en enero puede ser mediocre en mayo, y en mayo habrá aparecido algo significativamente mejor y más barato. Una empresa que apostó exclusivamente por un modelo de lenguaje específico en 2024 puede encontrarse pagando precios de tokens superiores por un modelo que ha sido superado en rendimiento por alternativas más económicas. La modularidad del stack de IA no es un detalle de arquitectura. Es una ventaja competitiva directa que se mide en coste de tokens y en velocidad de adopción de mejoras.
El plano de control común: gobierno centralizado, ejecución distribuida
Si hay una decisión arquitectónica que separa los proyectos de IA que escalan de los que se quedan en piloto, es la presencia o ausencia de un plano de control común. En la mayoría de proyectos, la secuencia es: identificar el caso de uso, construir el agente, integrarlo, desplegarlo, medir. Gobierno se añade después, cuando ya hay problemas. Esa secuencia es cara y lenta porque resuelve los problemas de gobierno uno a uno, en producción, bajo presión. El resultado más común es que cada unidad de negocio construye sus flujos en plataformas distintas, con criterios distintos, sin reutilización de capacidades comunes. Un caos técnico perfectamente predecible y perfectamente evitable.
El plano de control común tiene un principio rector: debe haber un único punto de decisión para los aspectos globales de la transformación. Qué plataforma de orquestación se usa. Qué modelos de lenguaje están autorizados. Cómo se gestiona el gasto en tokens. Qué capacidades son transversales y deben reutilizarse por todos los casos de uso en lugar de reimplementarse en cada uno. Este gobierno centralizado no implica que todo lo haga el mismo equipo. Implica que todos los que hacen cosas siguen las mismas pautas, establecidas por un único punto de autoridad técnica.
Gobierno centralizado, ejecución distribuida y competitiva
La tensión aparente entre gobierno centralizado y velocidad de desarrollo se resuelve con un modelo de dos capas. La primera: governance centralizado (plataforma, estándares, capacidades transversales, control de gasto, auditoría). La segunda: ejecución distribuida y competitiva, donde distintos integradores construyen flujos y agentes siguiendo esos estándares. La competencia entre integradores no es una debilidad del modelo: es un mecanismo de mejora continua. Los integradores que construyen mejor reciben más encargos. Los que no cumplen los estándares o no entregan calidad son sustituidos. Este modelo es incompatible con el enfoque de «un solo integrador lo hace todo», que elimina la presión de mejora y hace imposible cambiar de proveedor sin reiniciar la transformación desde cero.
Hay un error específico que este modelo previene y que vale la pena nombrar explícitamente: permitir que los proveedores automaticen en su propia nube privada. Cuando un proveedor de plataforma convence a la empresa de que sus agentes sean flujos nativos de esa plataforma, que solo funcionan con su infraestructura y que los datos residen en su cloud, la empresa ha cedido el control de su transformación al proveedor. Cambiar en ese escenario no es una decisión de negocio. Es una migración técnica de alta complejidad que convierte a la empresa en prisionera del vendor indefinidamente.
Los seis componentes de control que no son opcionales
- Identidad por agente: Cada agente de IA necesita una identidad gestionable, auditable y revocable, igual que un empleado humano. Sin identidad por agente no hay forma de saber qué agente tomó qué acción en qué momento sobre qué sistema. En sectores regulados —banca, seguros, salud— esto no es un requisito de seguridad opcional.
- Políticas y guardrails: Los agentes operan dentro de límites explícitos: qué datos pueden acceder, qué acciones pueden ejecutar sin aprobación humana, qué situaciones deben escalar obligatoriamente. Sin políticas explícitas, los agentes toman decisiones fuera de contexto sobre contratos, facturación y datos sensibles de clientes.
- FinOps — control de tokens y coste: El coste de un despliegue agentico a escala no es fijo. Depende del volumen de interacciones, la complejidad de los modelos y la longitud de los contextos procesados. Sin monitorización y control de gasto en tokens, una empresa puede encontrar facturas de infraestructura de IA tres veces superiores al presupuesto en el momento en que el despliegue empieza a escalar. FinOps para IA es un control de gestión, no una herramienta técnica.
- Auditoría y trazabilidad completa: Cada acción ejecutada por cualquier agente debe quedar registrada para poder diagnosticar decisiones incorrectas, entrenar modelos con casos de error y mejorar las políticas de escalado. Sin trazabilidad, la mejora continua del sistema es imposible.
- Gestión del ciclo de vida: Los agentes se despliegan, se actualizan y se retiran. El modelo que funciona hoy puede degradar su precisión en seis meses si los datos sobre los que fue entrenado han cambiado. Gestionarlos con la misma disciplina que el software de producción es un requisito operativo.
- Capacidades transversales reutilizables: Autenticación, logging, conectores a sistemas de back-end, gestión de contexto de cliente, plantillas de respuesta. Estas capacidades deben construirse una vez y estar disponibles para todos los flujos y agentes. Cada integrador que las reimplementa desde cero multiplica el coste y crea inconsistencias operativas.
Human-On-The-Loop: el control humano como diseño, no como freno
Uno de los debates más recurrentes en los proyectos de IA para contact center es el rol del agente humano. Hay dos posiciones extremas que ambas se equivocan. La primera: «la IA reemplazará a los agentes humanos». La segunda: «siempre necesitaremos un humano aprobando cada acción». La realidad operativa que demuestran los despliegues maduros es diferente, y se articula en el concepto de Human-On-The-Loop.
Human-In-The-Loop significa que el humano aprueba cada acción antes de ejecutarse. Es el modelo correcto para situaciones de alto riesgo y baja frecuencia: un caso de fraude complejo, una excepción de política que requiere autorización directiva, una situación legalmente sensible. Aplicado a todas las interacciones de un contact center con millones de contactos al mes, es un cuello de botella que impide escalar. Human-On-The-Loop es un modelo distinto: el sistema actúa de forma autónoma dentro de los límites de las políticas definidas, el humano supervisa el conjunto, recibe alertas cuando el sistema detecta casos fuera de los parámetros normales, y puede intervenir en cualquier momento sin necesidad de aprobar cada acción individualmente.
La implicación para el contact center: el modelo no reduce la plantilla, cambia su función. Los agentes que antes gestionaban consultas repetitivas pasan a supervisar el sistema, a gestionar los casos escalados, y a participar en la mejora continua del modelo (identificando respuestas incorrectas, documentando casos nuevos, actualizando la base de conocimiento). La productividad del mismo número de personas no se multiplica por dos. Se multiplica por un orden de magnitud diferente. El coste por interacción resuelta baja de forma significativa no porque haya menos agentes, sino porque cada agente hace trabajo que antes no podía hacer.
La prueba real: resultados en producción, no en piloto
Los modelos arquitectónicos son convincentes sobre el papel. Lo que los convierte en argumento irrefutable son resultados en producción, a escala, en condiciones reales. El caso de referencia más documentado de esta transformación en servicios complejos es el de una de las mayores organizaciones de soporte global del mundo, con más de 280 millones de contactos al año gestionados por más de 11.000 agentes distribuidos en más de 80 países en más de 50 idiomas. No como benchmark de sector. Como laboratorio de validación propio: la organización aplicó este modelo a su propia operación de soporte antes de ofrecerlo al mercado.
Los resultados del primer año de transformación fijan el nivel de referencia:
- ROI superior al 45% en el primer año, derivado de la migración de voz a IVR conversacional. No en año tres de la transformación. En el primer año, con el despliegue inicial.
- Más del 80% de reducción de coste por caso resuelto autónomamente respecto a la resolución por agente humano. No el coste marginal de añadir un canal digital. El coste comparativo real entre dos modelos de resolución a escala.
- Mejora radical en Calidad tanto a nivel de proceso tanto en customer surveys como churn.
Lo que distingue a este caso de los que circulan habitualmente es la ausencia de condiciones controladas de laboratorio. Es el sistema de soporte completo de una organización global, funcionando en producción real, con las métricas expuestas. Los resultados no son consecuencia de un entorno ideal. Son consecuencia de una arquitectura que funciona bajo la presión operativa real de un entorno a escala.

El orden correcto para hacer la transformación
La pregunta práctica es la que importa: ¿cómo se pasa del modelo actual al modelo descrito? La respuesta no es «contratar un proveedor de IA y esperar». Es una secuencia de decisiones con un orden no arbitrario. Invertirlo o saltarse pasos son las dos formas más comunes de convertir una transformación con potencial real en otro piloto que no escala.
Paso 1: Construir la capa de datos primero
Antes de implementar ningún agente de IA hay que responder a esta pregunta: ¿podría un agente humano nuevo resolver un caso complejo de cliente en menos de cinco minutos, accediendo a toda la información disponible sobre ese cliente, sin moverse de una sola pantalla? Si la respuesta es no, la capa de datos no está preparada para la IA. Construir el lago lógico unificado, definir la ontología de negocio y establecer los agentes de datos que mantienen esa capa actualizada no produce resultados visibles en los primeros meses. Es también la razón por la que la mayoría de proyectos no lo hacen y la razón por la que la mayoría fracasan.
Paso 2: Rediseñar el proceso antes de automatizarlo
Una vez que la capa de datos está disponible, el siguiente paso no es desplegar IA. Es rediseñar los procesos de atención partiendo de cero: si pudiéramos diseñar este proceso hoy, sabiendo lo que la IA puede hacer, ¿cómo lo diseñaríamos? La respuesta es siempre diferente al proceso existente, porque el proceso existente fue diseñado para un mundo sin datos unificados, sin modelos de lenguaje y sin agentes autónomos. El rediseño incluye definir qué tipos de interacciones se gestionan de forma autónoma, cuáles requieren asistencia de IA con supervisión humana y cuáles requieren intervención humana directa.
Paso 3: Construir el plano de gobierno antes de escalar
El plano de control común debe estar operativo antes de que los primeros agentes lleguen a producción. Implementar governance después es entre tres y cinco veces más caro porque implica retrofitting sobre una arquitectura ya en funcionamiento. Identidad, políticas, trazabilidad, FinOps, gestión de ciclo de vida, capacidades transversales: estos elementos deben estar funcionando en el momento en que el primer agente empieza a tomar decisiones autónomas sobre casos reales.
Paso 4: Empezar con casos de uso acotados, iterativos y con métricas claras
El primer despliegue en producción no debería ser el chatbot de atención general. Debería ser el caso de uso donde el problema está más claramente definido, los datos son más limpios y la métrica de éxito es más objetiva. En banca puede ser la clasificación automática de disputas de cargo. En seguros, la gestión de consultas sobre el estado de reclamaciones simples. En retail, las consultas de estado de pedido. En cualquier sector: casos donde el proceso está bien definido, el dato existe y el resultado es medible. La selección del primer caso no es una decisión técnica. Es una decisión estratégica sobre con qué construir la credibilidad del programa de transformación.
El desarrollo de ese primer caso debe ser iterativo desde el primer día: construcción conjunta entre el responsable del proceso y el integrador, resultados visibles en semanas, ajuste continuo del comportamiento del agente basado en lo que se observa en producción real. La distinción entre «desarrollo» y «producción» se difumina deliberadamente: el agente aprende de los casos reales más rápido que de ningún entorno de test.
Paso 5: Escalar con feedback loop y mejora continua
El modelo maduro no es un sistema estático que se despliega una vez. Cada resolución de un agente humano que supone una mejora sobre la respuesta del sistema se captura automáticamente, se procesa por un agente de generación de conocimiento y se incorpora a la base de conocimiento sin intervención editorial manual. El tiempo de actualización del sistema pasa de semanas a horas o días. En sectores con regulación o condiciones comerciales cambiantes, ese ciclo de actualización es una ventaja operativa que se acumula con el tiempo.
El modelo de personas: la comunidad que hace sostenible la transformación
La transformación con IA tiene un componente técnico y un componente organizativo. Las empresas que fallan en el primero suelen recuperarse. Las que fallan en el segundo no escalan, independientemente de la calidad de la tecnología. El componente organizativo tiene dos dimensiones: cómo se asigna la propiedad de los procesos, y cómo se construye la comunidad de personas que hace que la transformación se extienda y mejore con el tiempo.
La propiedad de proceso como principio organizativo
El modelo de organización que ha demostrado funcionar en las transformaciones que escalan es simple pero requiere disciplina para implementarlo: cada responsable de negocio es dueño de un proceso y responde por sus métricas de IA. No es responsabilidad compartida de IT y negocio. No es responsabilidad de un Centro de Excelencia de IA. Es responsabilidad individual del responsable del proceso, con un interlocutor técnico nominado en su equipo que reporta a esa persona y también forma parte de la comunidad técnica global.
Este modelo elimina el gap entre quién diseña el proceso y quién responde por sus resultados. Y genera un incentivo directo para que el responsable del proceso entienda lo que la IA hace en su proceso, porque es él quien responde cuando los resultados no son los esperados. La ignorancia tecnológica del responsable del proceso deja de ser un problema personal y se convierte en un riesgo de negocio visible y medible.
La Agentic League: la comunidad como infraestructura del cambio
El segundo componente es la comunidad. Una transformación de esta escala no se ejecuta solo con proyectos top-down. Requiere una comunidad de práctica activa, con niveles de expertise reconocidos, incentivos para participar y mecanismos para que el conocimiento fluya entre equipos. Las organizaciones que están consiguiendo los mejores resultados en transformación agentica han creado comunidades internas con nombre propio que generan orgullo de pertenencia —una Agentic League, o cualquier denominación que en la cultura de la organización comunique que pertenecer a ese grupo es un reconocimiento, no una obligación administrativa.
La estructura de esa comunidad tiene componentes no negociables:
- Niveles reconocidos: Equivalentes a green belt, black belt o cualquier estructura que diferencie entre quien está aprendiendo, quien es practicante activo y quien puede enseñar a otros. Esos niveles se obtienen mediante certificación, no por antigüedad ni por título.
- Entorno de práctica con herramientas reales: Los miembros necesitan acceso a los entornos donde se construyen los agentes, a los datos de prueba y a los recursos de cómputo que permiten experimentar. Una comunidad cuyos miembros quieren aprender pero no tienen herramientas genera frustración activa y pierde el capital humano que podría ser el mayor activo de la transformación.
- Espacio de compartición activo: No una intranet con documentos. Un espacio donde los miembros comparten los flujos que han construido, los errores que han cometido, las mejoras que han encontrado. Con eventos regulares, píldoras de conocimiento semanales y casos de uso comentados por quien los construyó. El conocimiento que no circula no multiplica.
- Incentivos reales por contribuir: Acceso prioritario a mejores licencias de modelos, formación avanzada, visibilidad en la organización, y puntos o reconocimiento por incorporar nuevos miembros. El crecimiento orgánico de la comunidad es más rápido y más sostenible que el reclutamiento centralizado.
- Proceso de certificación: Asegura un nivel mínimo de competencia antes de que alguien construya flujos y agentes en producción, y convierte el aprendizaje en un objetivo con hito claro. La certificación no tiene que ser un examen de tres horas. Puede ser la demostración de que se ha construido y desplegado un agente funcional en un entorno controlado.
El error que convierte una buena iniciativa de comunidad en un fracaso es conocido: ofrecer formación que no aporta valor práctico inmediato. Una formación sobre qué es la IA generativa dirigida a personas que ya usan modelos de lenguaje en su trabajo diario no capacita. La formación de la comunidad debe partir de dónde está realmente cada miembro, enseñar lo que no saben hacer todavía, y terminar con algo que pueden usar el día siguiente. Cualquier otra formación es coste sin retorno.
Conclusión: la ventana está abierta, pero no indefinidamente
La transformación de los procesos de cliente en grandes organizaciones de servicios hacia un modelo de inteligencia conversacional unificada no es una tendencia emergente. Es una arquitectura en producción con resultados documentados, disponible para cualquier organización que esté dispuesta a hacer el trabajo previo en el orden correcto: datos primero, proceso después, gobierno antes de escalar, IA sobre lo que ya funciona, comunidad de personas que sustente la mejora continua.
La IA no transforma los procesos de cliente. Los amplifica. Si lo que amplifica es un proceso bien diseñado, datos unificados, un gobierno sólido y una comunidad con criterio para construir y evolucionar agentes, el resultado es el que demuestran los casos de referencia. Si lo que amplifica es el modelo fragmentado actual, el resultado es el modelo fragmentado amplificado: más transferencias, más rellamadas, más sistemas, más coste. La elección no está en la tecnología. Está en el orden en que se hacen las cosas y en si la organización está dispuesta a construir las bases antes de pedir los resultados.
En Transformalix, trabajamos con organizaciones de servicios en el diseño y ejecución de esta transformación con el orden correcto: primero los datos y el proceso, luego la arquitectura agentica y el gobierno, luego el escalado y la comunidad. Si tu contact center sigue operando con más de diez sistemas abiertos por turno y una tasa de rellamada que no baja, hablemos sobre cuánto está costando ese modelo y qué se puede cambiar en los próximos seis meses.


